![]()
[Feb-2022] Pass Microsoft DP-100 Tests Engine pdf - All Free Dumps
Designing and Implementing a Data Science Solution on Azure Practice Tests 2022 | Pass DP-100 with confidence!
Step 4: Training with Practice Tests
Practicing more and more before taking the exam can help you score better. Using practice tests, you can also significantly improve your time management skills. You can easily find the relevant practice questions on different online learning platforms.
Schedule exam
Languages: English, Japanese, Chinese (Simplified), Korean
Retirement date: none
This exam measures your ability to accomplish the following technical tasks: manage Azure resources for machine learning; run experiments and train models; deploy and operationalize machine learning solutions; and implement responsible machine learning.
NEW QUESTION 119
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are analyzing a numerical dataset which contains missing values in several columns.
You must clean the missing values using an appropriate operation without affecting the dimensionality of the feature set.
You need to analyze a full dataset to include all values.
Solution: Remove the entire column that contains the missing data point.
Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
Explanation:
Use the Multiple Imputation by Chained Equations (MICE) method.
References:
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3074241/
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/clean-missing-data
NEW QUESTION 120
You need to implement early stopping criteria as suited in the model training requirements.
Which three code segments should you use to develop the solution? To answer, move the appropriate code segments from the list of code segments to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.
Answer:
Explanation: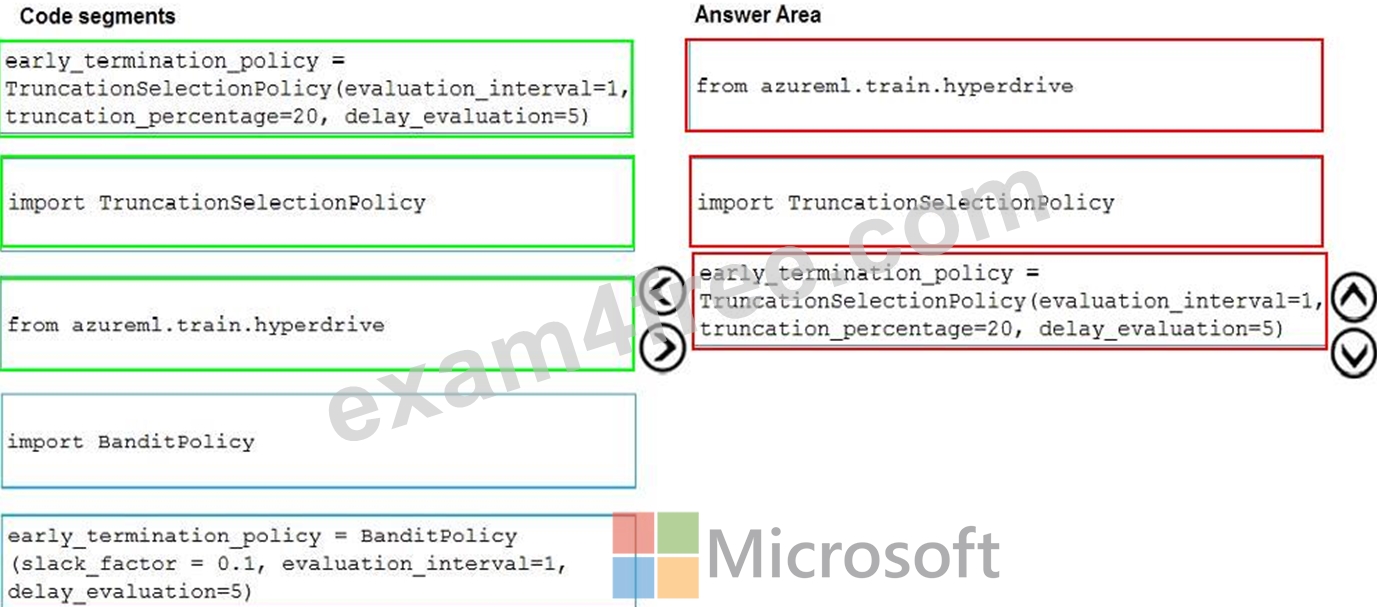
Explanation:
You need to implement an early stopping criterion on models that provides savings without terminating promising jobs.
Truncation selection cancels a given percentage of lowest performing runs at each evaluation interval. Runs are compared based on their performance on the primary metric and the lowest X% are terminated.
Example:
from azureml.train.hyperdrive import TruncationSelectionPolicy
early_termination_policy = TruncationSelectionPolicy(evaluation_interval=1, truncation_percentage=20, delay_evaluation=5) Incorrect Answers:
Bandit is a termination policy based on slack factor/slack amount and evaluation interval. The policy early terminates any runs where the primary metric is not within the specified slack factor / slack amount with respect to the best performing training run.
Example:
from azureml.train.hyperdrive import BanditPolicy
early_termination_policy = BanditPolicy(slack_factor = 0.1, evaluation_interval=1, delay_evaluation=5 References:
https://docs.microsoft.com/en-us/azure/machine-learning/service/how-to-tune-hyperparameters
NEW QUESTION 121
You are developing a linear regression model in Azure Machine Learning Studio. You run an experiment to compare different algorithms.
The following image displays the results dataset output: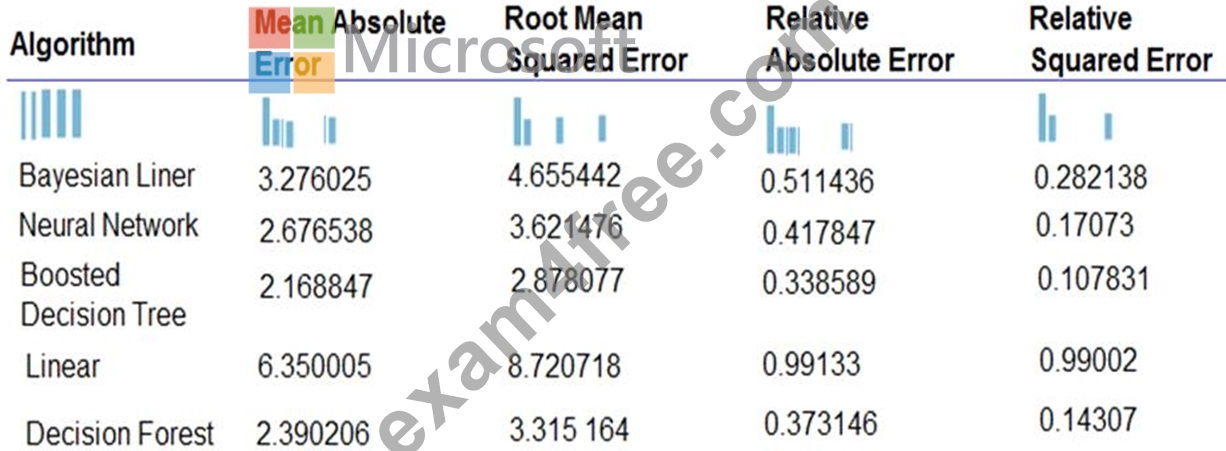
Use the drop-down menus to select the answer choice that answers each question based on the information presented in the image.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
Box 1: Boosted Decision Tree Regression
Mean absolute error (MAE) measures how close the predictions are to the actual outcomes; thus, a lower score is better.
Box 2:
Online Gradient Descent: If you want the algorithm to find the best parameters for you, set Create trainer mode option to Parameter Range. You can then specify multiple values for the algorithm to try.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/evaluate-model
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/linear-regression
NEW QUESTION 122
You create an experiment in Azure Machine Learning Studio- You add a training dataset that contains 10.000 rows. The first 9.000 rows represent class 0 (90 percent). The first 1.000 rows represent class 1 (10 percent).
The training set is unbalanced between two Classes. You must increase the number of training examples for class 1 to 4,000 by using data rows. You add the Synthetic Minority Oversampling Technique (SMOTE) module to the experiment.
You need to configure the module.
Which values should you use? To answer, select the appropriate options in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: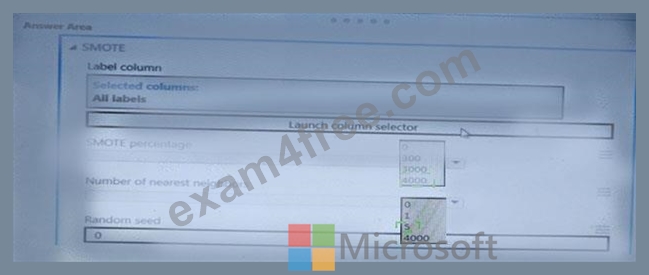
NEW QUESTION 123
You are moving a large dataset from Azure Machine Learning Studio to a Weka environment.
You need to format the data for the Weka environment.
Which module should you use?
- A. Convert to SVMLight
- B. Convert to CSV
- C. Convert to ARFF
- D. Convert to Dataset
Answer: C
Explanation:
Use the Convert to ARFF module in Azure Machine Learning Studio, to convert datasets and results in Azure Machine Learning to the attribute-relation file format used by the Weka toolset. This format is known as ARFF.
The ARFF data specification for Weka supports multiple machine learning tasks, including data preprocessing, classification, and feature selection. In this format, data is organized by entites and their attributes, and is contained in a single text file.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/convert-to-arff Prepare data for modeling Testlet 1 Case study Overview You are a data scientist in a company that provides data science for professional sporting events. Models will use global and local market data to meet the following business goals:
* Understand sentiment of mobile device users at sporting events based on audio from crowd reactions.
* Assess a user's tendency to respond to an advertisement.
* Customize styles of ads served on mobile devices.
* Use video to detect penalty events
Current environment
* Media used for penalty event detection will be provided by consumer devices. Media may include images and videos captured during the sporting event and shared using social media. The images and videos will have varying sizes and formats.
* The data available for model building comprises of seven years of sporting event media. The sporting event media includes; recorded video transcripts or radio commentary, and logs from related social media feeds captured during the sporting events.
* Crowd sentiment will include audio recordings submitted by event attendees in both mono and stereo formats.
Penalty detection and sentiment
* Data scientists must build an intelligent solution by using multiple machine learning models for penalty event detection.
* Data scientists must build notebooks in a local environment using automatic feature engineering and model building in machine learning pipelines.
* Notebooks must be deployed to retrain by using Spark instances with dynamic worker allocation.
* Notebooks must execute with the same code on new Spark instances to recode only the source of the data.
* Global penalty detection models must be trained by using dynamic runtime graph computation during training.
* Local penalty detection models must be written by using BrainScript.
* Experiments for local crowd sentiment models must combine local penalty detection data.
* Crowd sentiment models must identify known sounds such as cheers and known catch phrases. Individual crowd sentiment models will detect similar sounds.
* All shared features for local models are continuous variables.
* Shared features must use double precision. Subsequent layers must have aggregate running mean and standard deviation metrics available.
Advertisements
During the initial weeks in production, the following was observed:
* Ad response rated declined.
* Drops were not consistent across ad styles.
* The distribution of features across training and production data are not consistent Analysis shows that, of the 100 numeric features on user location and behavior, the 47 features that come from location sources are being used as raw features. A suggested experiment to remedy the bias and variance issue is to engineer 10 linearly uncorrelated features.
* Initial data discovery shows a wide range of densities of target states in training data used for crowd sentiment models.
* All penalty detection models show inference phases using a Stochastic Gradient Descent (SGD) are running too slow.
* Audio samples show that the length of a catch phrase varies between 25%-47% depending on region
* The performance of the global penalty detection models shows lower variance but higher bias when comparing training and validation sets. Before implementing any feature changes, you must confirm the bias and variance using all training and validation cases.
* Ad response models must be trained at the beginning of each event and applied during the sporting event.
* Market segmentation models must optimize for similar ad response history.
* Sampling must guarantee mutual and collective exclusively between local and global segmentation models that share the same features.
* Local market segmentation models will be applied before determining a user's propensity to respond to an advertisement.
* Ad response models must support non-linear boundaries of features.
* The ad propensity model uses a cut threshold is 0.45 and retrains occur if weighted Kappa deviated from
0.1 +/- 5%.
* The ad propensity model uses cost factors shown in the following diagram:
* The ad propensity model uses proposed cost factors shown in the following diagram:
* Performance curves of current and proposed cost factor scenarios are shown in the following diagram:
NEW QUESTION 124
You have a model with a large difference between the training and validation error values.
You must create a new model and perform cross-validation.
You need to identify a parameter set for the new model using Azure Machine Learning Studio.
Which module you should use for each step? To answer, drag the appropriate modules to the correct steps. Each module may be used once or more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
Box 1: Split data
Box 2: Partition and Sample
Box 3: Two-Class Boosted Decision Tree
Box 4: Tune Model Hyperparameters
Integrated train and tune: You configure a set of parameters to use, and then let the module iterate over multiple combinations, measuring accuracy until it finds a "best" model. With most learner modules, you can choose which parameters should be changed during the training process, and which should remain fixed.
We recommend that you use Cross-Validate Model to establish the goodness of the model given the specified parameters. Use Tune Model Hyperparameters to identify the optimal parameters.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/partition-and-sample
NEW QUESTION 125
You arc I mating a deep learning model to identify cats and dogs. You have 25,000 color images.
You must meet the following requirements:
* Reduce the number of training epochs.
* Reduce the size of the neural network.
* Reduce over-fitting of the neural network.
You need to select the image modification values.
Which value should you use? To answer, select the appropriate Options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: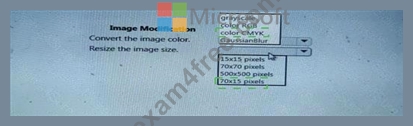
NEW QUESTION 126
You write a Python script that processes data in a comma-separated values (CSV) file.
You plan to run this script as an Azure Machine Learning experiment.
The script loads the data and determines the number of rows it contains using the following code: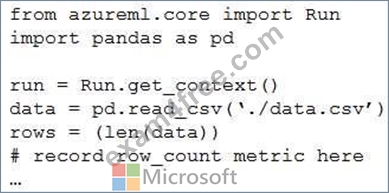
You need to record the row count as a metric named row_count that can be returned using the get_metrics method of the Run object after the experiment run completes.
Which code should you use?
- A. run.log('row_count', rows)
- B. run.tag('row_count', rows)
- C. run.upload_file('row_count', './data.csv')
- D. run.log_table('row_count', rows)
- E. run.log_row('row_count', rows)
Answer: A
Explanation:
Log a numerical or string value to the run with the given name using log(name, value, description=''). Logging a metric to a run causes that metric to be stored in the run record in the experiment. You can log the same metric multiple times within a run, the result being considered a vector of that metric.
Example: run.log("accuracy", 0.95)
Incorrect Answers:
E: Using log_row(name, description=None, **kwargs) creates a metric with multiple columns as described in kwargs. Each named parameter generates a column with the value specified. log_row can be called once to log an arbitrary tuple, or multiple times in a loop to generate a complete table.
Example: run.log_row("Y over X", x=1, y=0.4)
Reference:
https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.run
NEW QUESTION 127
You create a machine learning model by using the Azure Machine Learning designer. You publish the model as a real-time service on an Azure Kubernetes Service (AKS) inference compute cluster. You make no change to the deployed endpoint configuration.
You need to provide application developers with the information they need to consume the endpoint.
Which two values should you provide to application developers? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. The name of the inference pipeline for the endpoint.
- B. The URL of the endpoint.
- C. The key for the endpoint.
- D. The name of the AKS cluster where the endpoint is hosted.
- E. The run ID of the inference pipeline experiment for the endpoint.
Answer: B,C
Explanation:
Deploying an Azure Machine Learning model as a web service creates a REST API endpoint. You can send data to this endpoint and receive the prediction returned by the model.
You create a web service when you deploy a model to your local environment, Azure Container Instances, Azure Kubernetes Service, or field-programmable gate arrays (FPGA). You retrieve the URI used to access the web service by using the Azure Machine Learning SDK. If authentication is enabled, you can also use the SDK to get the authentication keys or tokens.
Example:
# URL for the web service
scoring_uri = '<your web service URI>'
# If the service is authenticated, set the key or token
key = '<your key or token>'
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-consume-web-service
NEW QUESTION 128
You are analyzing a raw dataset that requires cleaning.
You must perform transformations and manipulations by using Azure Machine Learning Studio.
You need to identify the correct modules to perform the transformations.
Which modules should you choose? To answer, drag the appropriate modules to the correct scenarios. Each module may be used once, more than once, or not at all.
You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
Box 1: Clean Missing Data
Box 2: SMOTE
Use the SMOTE module in Azure Machine Learning Studio to increase the number of underepresented cases in a dataset used for machine learning. SMOTE is a better way of increasing the number of rare cases than simply duplicating existing cases.
Box 3: Convert to Indicator Values
Use the Convert to Indicator Values module in Azure Machine Learning Studio. The purpose of this module is to convert columns that contain categorical values into a series of binary indicator columns that can more easily be used as features in a machine learning model.
Box 4: Remove Duplicate Rows
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/smote
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/convert-to-indicator-values
NEW QUESTION 129
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are analyzing a numerical dataset which contains missing values in several columns.
You must clean the missing values using an appropriate operation without affecting the dimensionality of the feature set.
You need to analyze a full dataset to include all values.
Solution: Replace each missing value using the Multiple Imputation by Chained Equations (MICE) method.
Does the solution meet the goal?
- A. Yes
- B. No
Answer: A
Explanation:
Replace using MICE: For each missing value, this option assigns a new value, which is calculated by using a method described in the statistical literature as "Multivariate Imputation using Chained Equations" or "Multiple Imputation by Chained Equations". With a multiple imputation method, each variable with missing data is modeled conditionally using the other variables in the data before filling in the missing values.
Note: Multivariate imputation by chained equations (MICE), sometimes called "fully conditional specification" or
"sequential regression multiple imputation" has emerged in the statistical literature as one principled method of addressing missing data. Creating multiple imputations, as opposed to single imputations, accounts for the statistical uncertainty in the imputations. In addition, the chained equations approach is very flexible and can handle variables of varying types (e.g., continuous or binary) as well as complexities such as bounds or survey skip patterns.
References:
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3074241/
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/clean-missing-data
NEW QUESTION 130
You have a Python data frame named salesData in the following format:
The data frame must be unpivoted to a long data format as follows: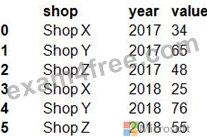
You need to use the pandas.melt() function in Python to perform the transformation.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.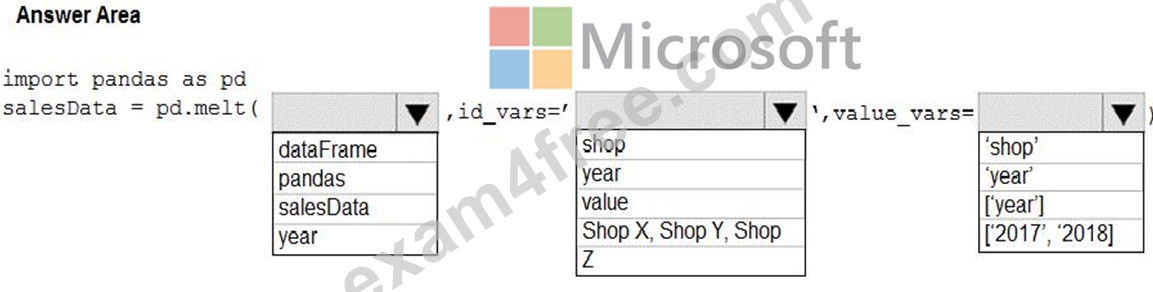
Answer:
Explanation: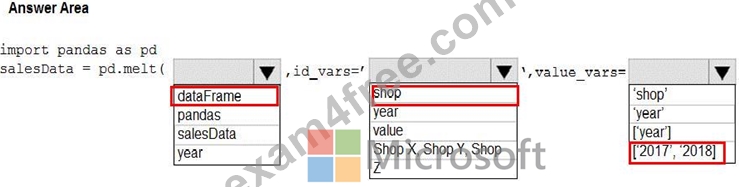
Explanation:
Box 1: dataFrame
Syntax: pandas.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None)[source] Where frame is a DataFrame Box 2: shop Paramter id_vars id_vars : tuple, list, or ndarray, optional Column(s) to use as identifier variables.
Box 3: ['2017','2018']
value_vars : tuple, list, or ndarray, optional
Column(s) to unpivot. If not specified, uses all columns that are not set as id_vars.
Example:
df = pd.DataFrame({'A': {0: 'a', 1: 'b', 2: 'c'},
... 'B': {0: 1, 1: 3, 2: 5},
... 'C': {0: 2, 1: 4, 2: 6}})
pd.melt(df, id_vars=['A'], value_vars=['B', 'C'])
A variable value
0 a B 1
1 b B 3
2 c B 5
3 a C 2
4 b C 4
5 c C 6
References:
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.melt.html
NEW QUESTION 131
You are performing sentiment analysis using a CSV file that includes 12,000 customer reviews written in a short sentence format. You add the CSV file to Azure Machine Learning Studio and configure it as the starting point dataset of an experiment. You add the Extract N-Gram Features from Text module to the experiment to extract key phrases from the customer review column in the dataset.
You must create a new n-gram dictionary from the customer review text and set the maximum n-gram size to trigrams.
What should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.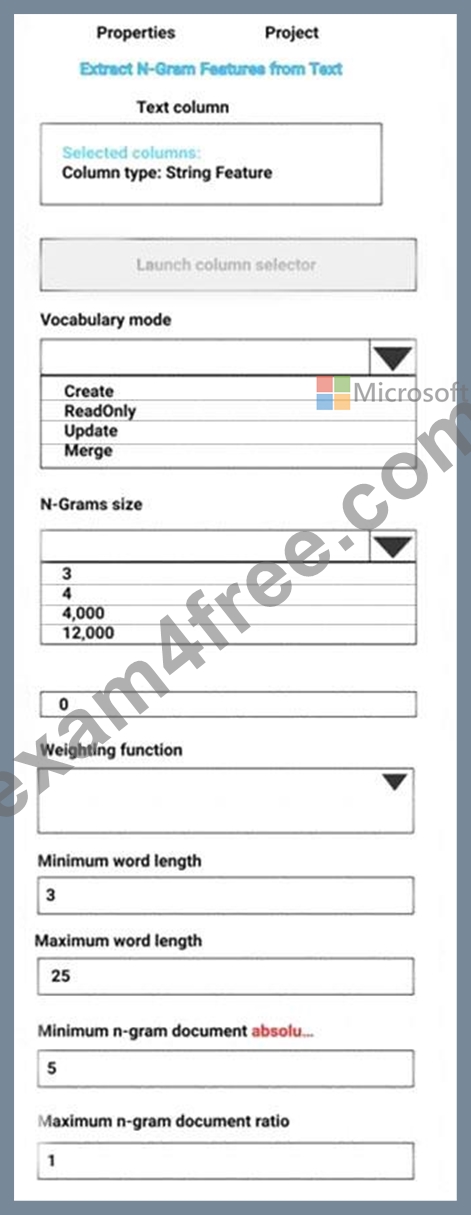
Answer:
Explanation:
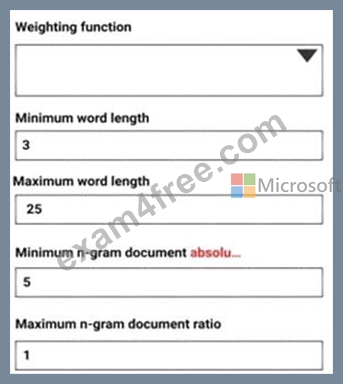
Explanation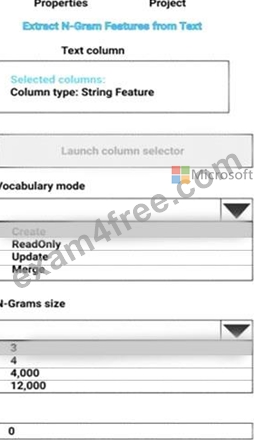
Vocabulary mode: Create
For Vocabulary mode, select Create to indicate that you are creating a new list of n-gram features.
N-Grams size: 3
For N-Grams size, type a number that indicates the maximum size of the n-grams to extract and store. For example, if you type 3, unigrams, bigrams, and trigrams will be created.
Weighting function: Leave blank
The option, Weighting function, is required only if you merge or update vocabularies. It specifies how terms in the two vocabularies and their scores should be weighted against each other.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/extract-n-gram-features-from-
NEW QUESTION 132
You create a datastore named training_data that references a blob container in an Azure Storage account. The blob container contains a folder named in which multiple comma-separated values (CSV) files are stored.
You have a script named train.py in a local folder named ./script that you plan to run as an experiment using an estimator. The script includes the following code to read data from the csv_files folder:
You have the following script.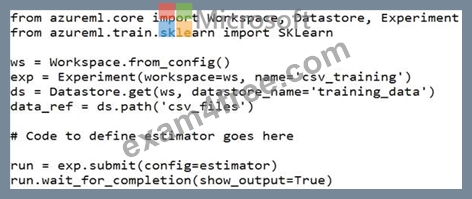
You need to configure the estimator for the experiment so that the script can read the data from a data reference named data_ref that references the csv_files folder in the training_data datastore.
Which code should you use to configure the estimator?
- A. Option B
- B. Option D
- C. Option C
- D. Option E
- E. Option A
Answer: A
Explanation:
Explanation
Besides passing the dataset through the inputs parameter in the estimator, you can also pass the dataset through script_params and get the data path (mounting point) in your training script via arguments. This way, you can keep your training script independent of azureml-sdk. In other words, you will be able use the same training script for local debugging and remote training on any cloud platform.
Example:
from azureml.train.sklearn import SKLearn
script_params = {
# mount the dataset on the remote compute and pass the mounted path as an argument to the training script
'--data-folder': mnist_ds.as_named_input('mnist').as_mount(),
'--regularization': 0.5
}
est = SKLearn(source_directory=script_folder,
script_params=script_params,
compute_target=compute_target,
environment_definition=env,
entry_script='train_mnist.py')
# Run the experiment
run = experiment.submit(est)
run.wait_for_completion(show_output=True)
Reference:
https://docs.microsoft.com/es-es/azure/machine-learning/how-to-train-with-datasets
NEW QUESTION 133
You plan to deliver a hands-on workshop to several students. The workshop will focus on creating data visualizations using Python. Each student will use a device that has internet access.
Student devices are not configured for Python development. Students do not have administrator access to install software on their devices. Azure subscriptions are not available for students.
You need to ensure that students can run Python-based data visualization code.
Which Azure tool should you use?
- A. Azure BatchAl
- B. Azure Machine Learning Service
- C. Anaconda Data Science Platform
- D. Azure Notebooks
Answer: D
Explanation:
References:
https://notebooks.azure.com/
NEW QUESTION 134
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
An IT department creates the following Azure resource groups and resources: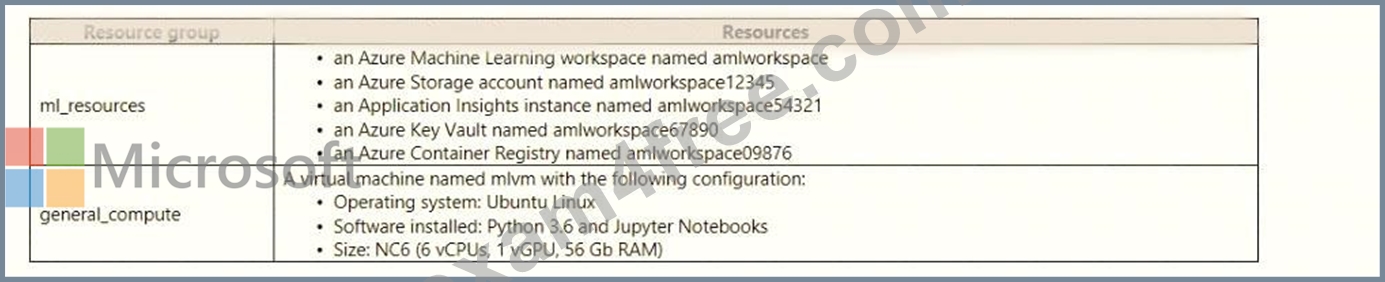
The IT department creates an Azure Kubernetes Service (AKS)-based inference compute target named aks-cluster in the Azure Machine Learning workspace.
You have a Microsoft Surface Book computer with a GPU. Python 3.6 and Visual Studio Code are installed.
You need to run a script that trains a deep neural network (DNN) model and logs the loss and accuracy metrics.
Solution: Install the Azure ML SDK on the Surface Book. Run Python code to connect to the workspace and then run the training script as an experiment on local compute.
- A. Yes
- B. No
Answer: B
Explanation:
Explanation
Need to attach the mlvm virtual machine as a compute target in the Azure Machine Learning workspace.
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/concept-compute-target
NEW QUESTION 135
You are implementing a machine learning model to predict stock prices.
The model uses a PostgreSQL database and requires GPU processing.
You need to create a virtual machine that is pre-configured with the required tools.
What should you do?
- A. Create a Deep Learning Virtual Machine (DLVM) Windows edition.
- B. Create a Deep Learning Virtual Machine (DLVM) Linux edition.
- C. Create a Geo Al Data Science Virtual Machine (Geo-DSVM) Windows edition.
- D. Create a Data Science Virtual Machine (DSVM) Windows edition.
Answer: D
Explanation:
In the DSVM, your training models can use deep learning algorithms on hardware that's based on graphics processing units (GPUs).
PostgreSQL is available for the following operating systems: Linux (all recent distributions), 64-bit installers available for macOS (OS X) version 10.6 and newer - Windows (with installers available for 64-bit version; tested on latest versions and back to Windows 2012 R2.
Incorrect Answers:
B: The Azure Geo AI Data Science VM (Geo-DSVM) delivers geospatial analytics capabilities from Microsoft's Data Science VM. Specifically, this VM extends the AI and data science toolkits in the Data Science VM by adding ESRI's market-leading ArcGIS Pro Geographic Information System.
C, D: DLVM is a template on top of DSVM image. In terms of the packages, GPU drivers etc are all there in the DSVM image. Mostly it is for convenience during creation where we only allow DLVM to be created on GPU VM instances on Azure.
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/data-science-virtual-machine/overview
NEW QUESTION 136
A coworker registers a datastore in a Machine Learning services workspace by using the following code: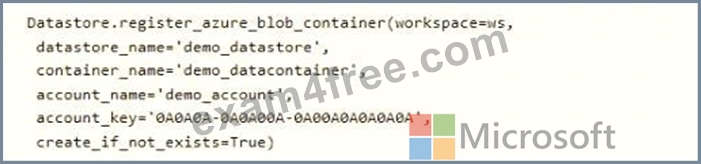
You need to write code to access the datastore from a notebook.
Answer:
Explanation:
Explanation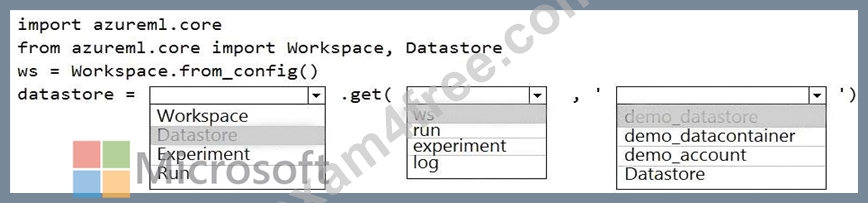
Box 1: DataStore
To get a specific datastore registered in the current workspace, use the get() static method on the Datastore class:
# Get a named datastore from the current workspace
datastore = Datastore.get(ws, datastore_name='your datastore name')
Box 2: ws
Box 3: demo_datastore
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-access-data
NEW QUESTION 137
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You create an Azure Machine Learning service datastore in a workspace. The datastore contains the following files:
* /data/2018/Q1.csv
* /data/2018/Q2.csv
* /data/2018/Q3.csv
* /data/2018/Q4.csv
* /data/2019/Q1.csv
All files store data in the following format:
id,f1,f2,I
1,1,2,0
2,1,1,1
3,2,1,0
4,2,2,1
You run the following code:
You need to create a dataset named training_data and load the data from all files into a single data frame by using the following code:
Solution: Run the following code:
Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
Explanation:
Define paths with two file paths instead.
Use Dataset.Tabular_from_delimeted as the data isn't cleansed.
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-create-register-datasets
NEW QUESTION 138
......
Ways to Getting DP-100 Exam-Ready
The kind of extensive subject matter for the Microsoft DP-100 can be only obtained once the aspirant has access to quality study resources that are in general endorsed by the vendor itself. Overall, Microsoft offers both free and paid training courses to gain demanded expertise for DP-100. When it comes to the gratis learning path, it contains the following self-paced classes:
- Create Machine Learning Model - This is an intermediate-level free training course with 5 modules that details every single fact you should know about ML and its functions, features, and tools. To enroll for this option, it’s advisable that you have some related experience with the Python programming language.
- Build AI Solutions with Machine Learning - This is the mid-tier class offered for those who want to get themselves familiarized with Azure ML Python SDK that is used for creating organizational-ready AI solutions. Consisting of 14 full-length parts, the training requires you to possess some experience dealing with Python, PyTorch, ML, Scikit-Learn, and Tensorflow.
- Create No-Code Predictive Models with Azure Machine Learning - In all, it’s beginner training that is composed of 4 concise modules that accentuate such technologies as data science, ML, Azure, and AI engineering. To be entitled to access this learning path and entirely apprehend all the details covered here, you are expected to have some skills in navigating the Azure portal.
As far as you can see, all these are the best options to consider when free learning resources for the Microsoft DP-100 exam are concerned. Still, there is one paid instructor-led training course as well. It covers the concepts related to Designing & Implementing a Data Science Solution on Azure and is known as Course DP-100T01-A, which is a 3-day long class explaining every bit of the exam domains. In particular, the course imparts in applicants the intermediate knowledge of ML solutions, Python to monitor data preparation & ingestion, and ML frameworks. During the whole training, you’ll get exposed to as many as 10 comprehensive modules that spin around the test objectives. What makes these lessons significant is that they contain labs in the curriculum unlike free self-paced learning, which allows you to develop practical skills that are generally necessary for job-oriented tasks. So, visit the vendor’s website, check whether you comply with the course prerequisites and if you do, enroll in it, and be entirely geared up for the Microsoft DP-100 exam.
Online Exam Practice Tests with detailed explanations!: https://torrentvce.exam4free.com/DP-100-valid-dumps.html